


Оценка качества генерируемых ответов в системе RAG-powered QA
Введение и контекст
В эпоху цифровой трансформации и экспоненциального роста информационных потоков системы вопросов и ответов (QA-системы) превратились в незаменимый инструмент для работы с данными. Современные пользователи нуждаются в мгновенном доступе к точной и актуальной информации, что критически важно для бизнеса, образования, здравоохранения и других сфер деятельности.
Для поддержания высокого качества обслуживания и надежности таких систем требуется комплексный подход к их оценке и оптимизации. Именно здесь на помощь приходит инновационная технология Retrieval-Augmented Generation (RAG), которая открывает новые возможности для анализа и улучшения качества генерируемых ответов. Внедрение методологии RAG позволяет не только выявлять слабые места в работе систем, но и существенно оптимизировать процессы извлечения и генерации информации, что напрямую влияет на удовлетворенность пользователей и эффективность взаимодействия с системой.
Принцип работы RAG
Retrieval-Augmented Generation представляет собой передовую технологию, объединяющую два ключевых компонента: извлечение информации и генерацию текста. Работа системы построена на последовательном выполнении двух этапов:
-
Извлечение данных: система анализирует базу знаний (Knowledge Base, KB) и находит наиболее релевантные документы или фрагменты информации, соответствующие запросу пользователя.
-
Генерация ответа: на основе извлеченных данных формируется финальный ответ, который сочетает в себе преимущества обоих подходов.
Ключевое преимущество RAG заключается в том, что система не ограничивается только предварительно обученными моделями, а активно использует актуальные данные из базы знаний. Это особенно важно при обработке сложных запросов, требующих глубокого анализа контекста и специализированных знаний.
Практическое применение
Технология RAG демонстрирует высокую эффективность в системах вопросов и ответов, где необходимо обеспечить:
-
Точность ответов при работе со сложными или специфическими запросами
-
Контекстуальное понимание при анализе пользовательских запросов
-
Актуальность информации за счет использования свежих данных из базы знаний
-
Качество взаимодействия между пользователем и системой
Благодаря комбинированному подходу к извлечению и генерации, системы на базе RAG способны предоставлять более точные, информативные и полезные ответы. Это делает их незаменимым инструментом не только для конечных пользователей, но и для бизнеса, стремящегося к повышению эффективности работы с информацией.
Оценка эффективности системы вопросов и ответов с использованием RAG
Метод позволяет оценить эффективность системы вопросов и ответов (QA), использующей технологию RAG (Retrieval-Augmented Generation), на основе анализа приемлемости генерируемых ответов.
Критерии оценки: Основным показателем успешности является доля приемлемых ответов, которая должна составлять не менее X% от общего числа.
Ответ признается приемлемым, если тестовый инженер подтверждает его пригодность для использования конечными пользователями, принимая во внимание:
- Контекстные особенности запроса
- Ограничения существующей базы знаний (KB) системы
- Соответствие ожиданиям реальных пользователей
Ограничения методики оценки
- Область применения. Методика направлена на тестирование непосредственно системы RAG, а не готового чат-бота, взаимодействующего с конечными пользователями.
- Зависимость от базы знаний. Качество генерируемых ответов прямо пропорционально точности и полноте используемой базы знаний (KB). Ответственность за качество данных в KB лежит на владельце базы, а не на разработчике системы RAG.
- Процедура оценки. Оценка должна проводиться представителями владельца KB для обеспечения соответствие ответов специфическому содержанию конкретной KB и валидации пригодности ответов для коммерческого использования.
- Функциональные ограничения. При отсутствии релевантного ответа в KB система RAG возвращает стандартное запасное сообщение. Система работает в изолированном режиме, т.е. извлечение информации происходит исключительно из KB, а доступ к интернету и внешним ИТ-системам отсутствует.
- Языковые требования. Тестирование проводится на том же языке, что и обучающая KB (однозначное соответствие: одна KB = один язык).
Методология тестирования
1. Определение целевого уровня приемлемости
На первом этапе необходимо установить количественный критерий успешности системы, выраженный в процентах успешных ответов. Этот показатель определяет минимальный порог эффективности, при достижении которого система считается соответствующей требованиям.
Пример формулировки: Система должна генерировать удовлетворительные ответы минимум на X% от общего числа тестовых запросов.
Важные аспекты:
- Целевой показатель должен быть реалистичным и достижимым
- Значение X% определяется на основе бизнес-требований и специфики задачи
- Критерии приемлемости ответа должны быть четко определены заранее
- Показатель может варьироваться в зависимости от приоритетности типов запросов
2. Выбор базы знаний для тестирования
На данном этапе необходимо определить конкретную базу знаний (KB), которая будет использоваться в процессе тестирования.
3. Формирование набора тестовых вопросов
3.1. Общие требования
- Минимальный объем: 120 тестовых вопросов
- Все вопросы должны быть составлены на том же языке, что и выбранная база знаний
- При тестировании мультимодальной системы RAG необходимо учитывать соответствующие форматы (текст/изображения)
3.2. Структура тестового набора
Основные вопросы (≥100 вопросов):
- Направлены на проверку работы с основной базой знаний
- Должны охватывать все ключевые разделы KB
- Количество вопросов должно коррелировать с размером базы знаний
- Формулировки должны быть конкретными и однозначными
Смежные вопросы (10% от вопросов по KB):
- Касаются тематически близких областей
- Не имеют прямых ответов в текущей KB
- Проверяют способность системы работать с пограничными случаями
Внешние вопросы (10% от вопросов по KB)
- Полностью выходят за рамки текущей базы знаний
- Проверяют способность системы корректно идентифицировать нерелевантные запросы
- Пример: для KB о торговле на Форекс: “Какой прогноз погоды на следующую неделю?”
3.3. Рекомендации по составлению
- Обеспечьте равномерное распределение вопросов по всем разделам KB
- Включите вопросы разной сложности
- Используйте различные формулировки для проверки гибкости системы
- Предусмотрите возможность расширения набора вопросов
- Документируйте источники и логику формирования вопросов
3.4. Критерии качества вопросов
- Релевантность выбранной базе знаний
- Ясность формулировки
- Отсутствие двусмысленности
- Соответствие целевой аудитории
- Полнота охвата предметной области
4. Определение требований к ответам
Тон общения: профессиональный, дружелюбный.
Ограничения по длине: ответы должны быть информативными и лаконичными.
Форматирование: используйте абзацы для разделения информации и подчёркивания ключевых моментов.
Ссылки и цитаты источников: при необходимости добавьте ссылки или цитаты для подтверждения информации.
При составлении ответов убедитесь, что они соответствуют информации, представленной в базе знаний. Также определите, какое сообщение будет отправлено пользователю в случае возникновения проблем или вопросов.
5. Обучение системы RAG
На этом этапе необходимо разработать и настроить систему RAG на основе выбранной базы знаний и требований к ответам.
6. Тестирование
Тестовые инженеры задают системе все тестовые вопросы и оценивают ответы как приемлемые или неприемлемые. Ответ считается приемлемым, если он фактически правильный и подходит для реальных пользователей.
Для вопросов без ответов в базе знаний запасное сообщение считается приемлемым. Для вопросов по смежной тематике приемлемыми ответами могут быть:
- запасное сообщение: «Извините, у меня нет ответа на этот вопрос»;
- соответствующий фактический ответ: «Криптовалюту нельзя продать на Форексе»;
- альтернатива на основе базы знаний: «У меня нет информации о торговле криптовалютой, но я могу объяснить торговлю на Форексе на платформе XXX».
7. Повторное тестирование с участием нескольких оценщиков
Проведите повторное тестирование с участием нескольких оценщиков, чтобы гарантировать надёжность и согласованность результатов. Оценщики должны независимо оценить те же ответы, чтобы выявить возможные различия в восприятии приемлемости. Сравните полученные результаты и обсудите возникшие разногласия для достижения консенсуса относительно критериев оценки.
Диагностическая структура от OpenAI
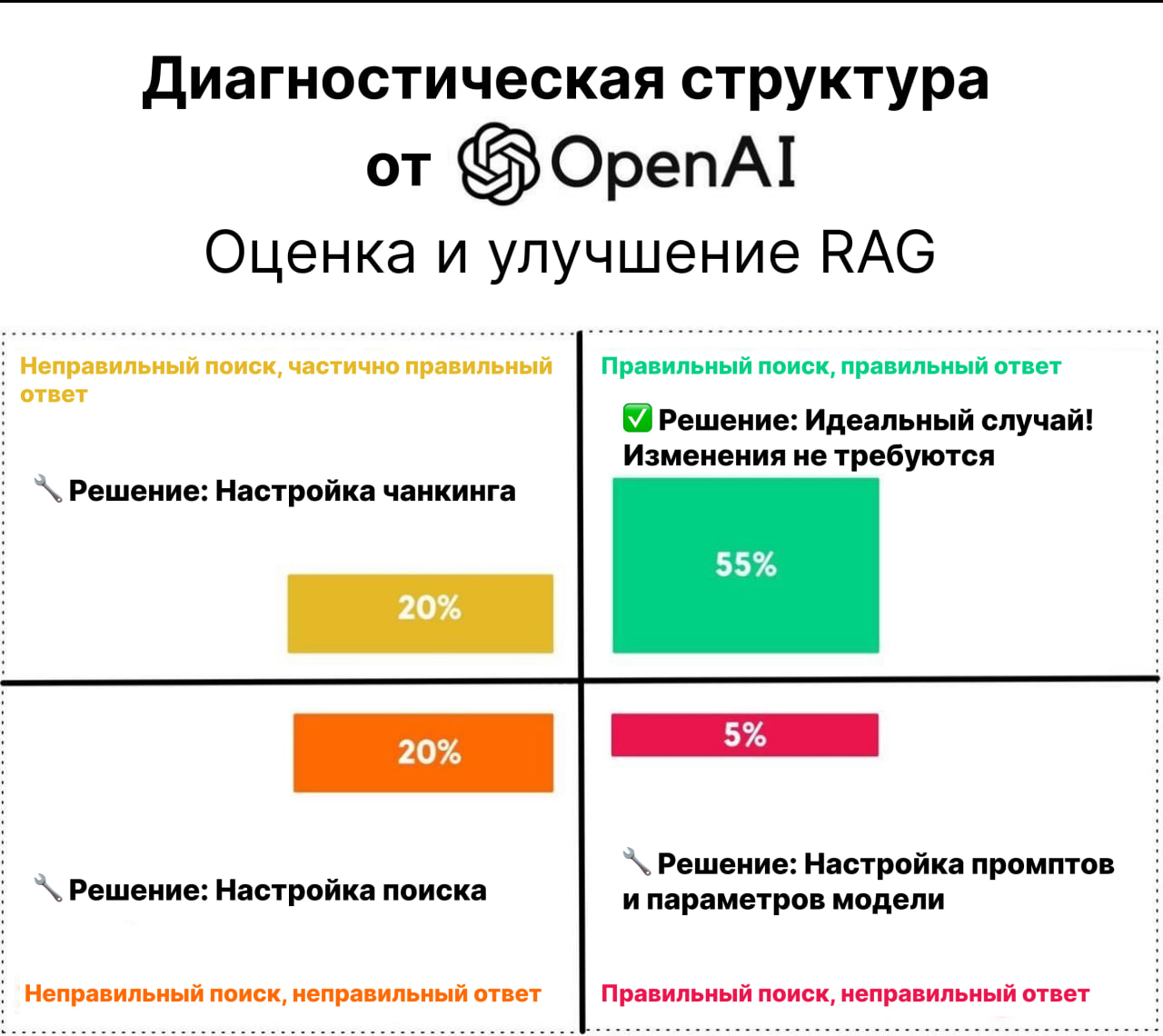
Эта структура помогает разбить проблему на два ключевых фактора:
📌 Качество поиска – была ли получена правильная информация?
📌 Качество ответа – был ли финальный ответ правильным?
Анализ квадрантов
✅ 55% – Правильный поиск и правильный ответ → Изменения не требуются! 🎯
🟠 20% – Неправильный поиск, но частично правильный ответ → Настройка чанкинга (корректировка способа деления и получения данных).
🔴 20% – Неправильный поиск и неправильный ответ → Настройка поиска (улучшение извлечения документов).
🟡 5% – Правильный поиск, но неправильный ответ → Настройка промптов/параметров модели (оптимизация генерации ответов).
Основной вывод
Если ваша модель работает не так, как ожидалось, сначала определите, связана ли проблема с извлечением информации или генерацией ответа. Затем оптимизируйте разделение, поиск или настройку подсказок соответственно.
Заключение
Метод оценки приемлемости ответов системы на основе RAG является важным этапом в обеспечении качества и надежности взаимодействия с пользователями. Систематический подход к тестированию и анализу ответов поможет выявить слабые места и улучшить общую производительность системы.
Ответим на ваши вопросы по чат-бот платформе chatme.ai
самое свежее:
09.04.2026
02.04.2026

Поделиться статьёй: